Форум StopLinux
- Темы: Активные | Без ответа
Объявление
Страницы 1
#1 02-07-11 18:43:24
- Babusha
- Нехристь

- Зарегистрирован: 12-03-10
- Сообщений: 2,160


Помогите разобраться с одной проблемой, в баше
Значит так, захотелось мне написать нормальную привязку find к ruby, где не будет бага с символом "\n", в чем смысл идеи, делаем однострочник в баше такой, что бы он печатал имена файлов в массив т.е
files[0] = '.'; files[1] = './.git'; files[2] = './.git/COMMIT_EDITMSG'; files[3] = './.git/config';А потом из руби его eval'им
Попробовал сделать вот так:
index=0; find #{arguments} -exec echo -n "files[$index] = {}"\; index=$((index + 1))\;Проблема в том, что, он только после того, как выполняет echo (!) для абсолютно всех файлов, только тогда выполняет index=$((index + 1))\;
Т.е сначала печатает весь массив, каждый елемент которого с индексом 0 (ноль)
files[0] = '.'; files[0] = './.git'; files[0] = './.git/COMMIT_EDITMSG'; files[0] = './.git/config';Что делать -- не имею представления, прошу местный людей прояснить мне ситуацию.
Кстати, да, собирался делать как-то так:
class File
def find(arguments = '')
files = Array.new
eval(%x[index=0; find #{arguments} -exec echo -n "files[$index] = {}"\; index=$((index + 1))\;].chomp())
end
endРедактировался Babusha (02-07-11 18:52:09)
Неактивен
#2 02-07-11 19:33:40
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Да просто всё.
Да мне не башевский массив нужен, мне нужно что бы печатался массив с синтаксисом руби, а уже из руби я бы его eval`ил. Кстати, да, насчет примеру твоего, если будет в имени файла пробел или символ "\n" то будет ошибка.
Редактировался Babusha (02-07-11 19:38:03)
Неактивен
#3 02-07-11 20:34:57
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
А что мешает сначала записать результат в строковую переменную, а потом удалить из него "лишние" символы?
А в том, что если имя файла будет hello\naabbbcc то тогда ничего не получиться.
Неактивен
#4 02-07-11 20:58:39
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Вообще, это как бы ненормальное имя файла. Так что правильным вариантом будет сначала переименовать все такие файлы, чтобы не мучаться.
Ты это скажи файловой системе.
Но можно и такие обработать, угадайте, как.
find -print0 | xargs ?
Не понял проблемы, если честно. Ты берёшь "сырую" строку, с "неправильными" символами и исправляешь так, чтобы она могла лечь в твой массив. Заменяешь или удаляешь "неправильные" символы - и потом уже парсишь.
Да нахер мне нужен башевский массив? Мне нужно что-бы сформировать из вывода find массив синтаксиса руби, зачем мне башевский массив?
Неактивен
#5 02-07-11 21:03:43
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Вы же не станете утверждать, что в inode будут недопустимые символы? Нет. Всё, можете делать с ними что угодно.
Если так, а точно не будет проблем с кривыми символами в именах?
UPD
Черт, так не подходит, есть нормальное решение?
Редактировался Babusha (02-07-11 21:05:27)
Неактивен
#6 02-07-11 21:18:40
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Зачем из bash передавать массив в ruby?
Что бы использовать его в Ruby, всегда ваш К.О.
Неактивен
#7 02-07-11 21:28:01
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
А почему в руби не обработать вывод команды find?
Можно, конечно %x[find].split("\n")
Но тогда будут глюки со спец символами.
Неактивен
#8 02-07-11 21:30:49
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Linups_Troolvalds, ну так ты можешь мне сказать, как через find и параметр -exec реализовать вывод типа:
files[0] = '.'; files[1] = './.git'; files[2] = './.git/COMMIT_EDITMSG'; files[3] = './.git/config';Ну как, скажи?
Добавлено спустя 02 мин 34 с:
Если у нас каждое имя заканчивается '\0', было бы странно резать по '\n', да.
А если в имени файла будет "\0" ?
Неактивен
#9 02-07-11 21:41:22
- Mazzy
- Посетитель зоопарка

- Зарегистрирован: 06-05-10
- Сообщений: 933

Re: Помогите разобраться с одной проблемой, в баше
Babusha, ну в самом деле-то!
в имени файла будет "\0"
hello\naabbbcc
Вы таких файлов много видели?
Неактивен
#10 02-07-11 23:14:52
- Babusha
- Нехристь
- Зарегистрирован: 12-03-10
- Сообщений: 2,160
Re: Помогите разобраться с одной проблемой, в баше
Вы таких файлов много видели?
Это же юнипс, тут все бывает.
Только мне постановка задачи всё равно не нравится.
Я кстати твой код разобрать не могу, вот блин, если бы еще выводилось как files[$index] = "path"; files[$index] = "path2"; в одну строку, да и еще какае-то странная особенность, почему-то счетчик index обнуляется и весь index начинает считать с самого начала, WTF?. 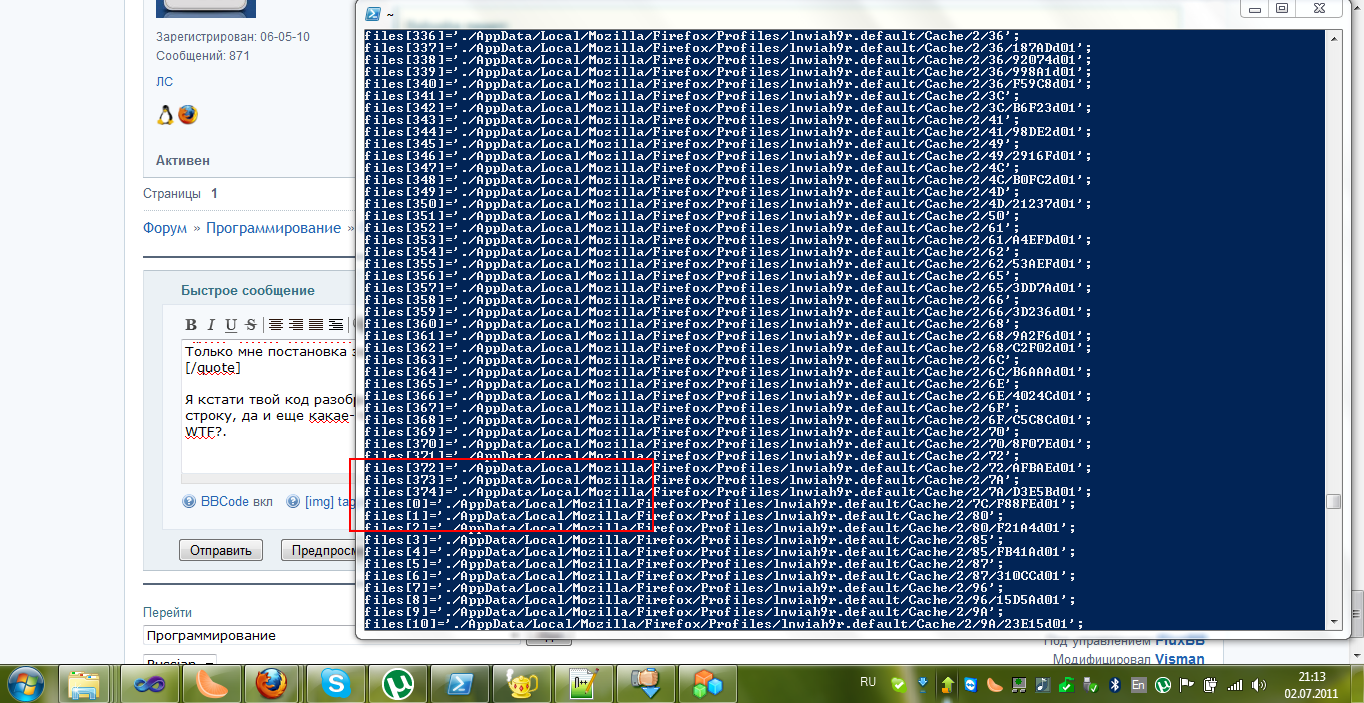
Редактировался Babusha (02-07-11 23:15:51)
Неактивен
#11 02-06-12 12:38:20
- fooser
- Участник

- Зарегистрирован: 02-06-12
- Сообщений: 692

Re: Помогите разобраться с одной проблемой, в баше
Babusha, я все же не понимаю зачем нужен такой неочевидный способ передачи данных, через eval? Это ведь небезопасно. Разве рубик не дает скриптам параметры своего запуска? По идее должен, следовательно куда уж проще было бы сделать нечто вроде ./имяскрипта --parameter1 value1 --parameter2 value2 и так далее. И тогда проблемы с кривыми символами ушли бы сами собой. Просто ваш изначальный подход is broken by design.
Неактивен
Страницы 1